
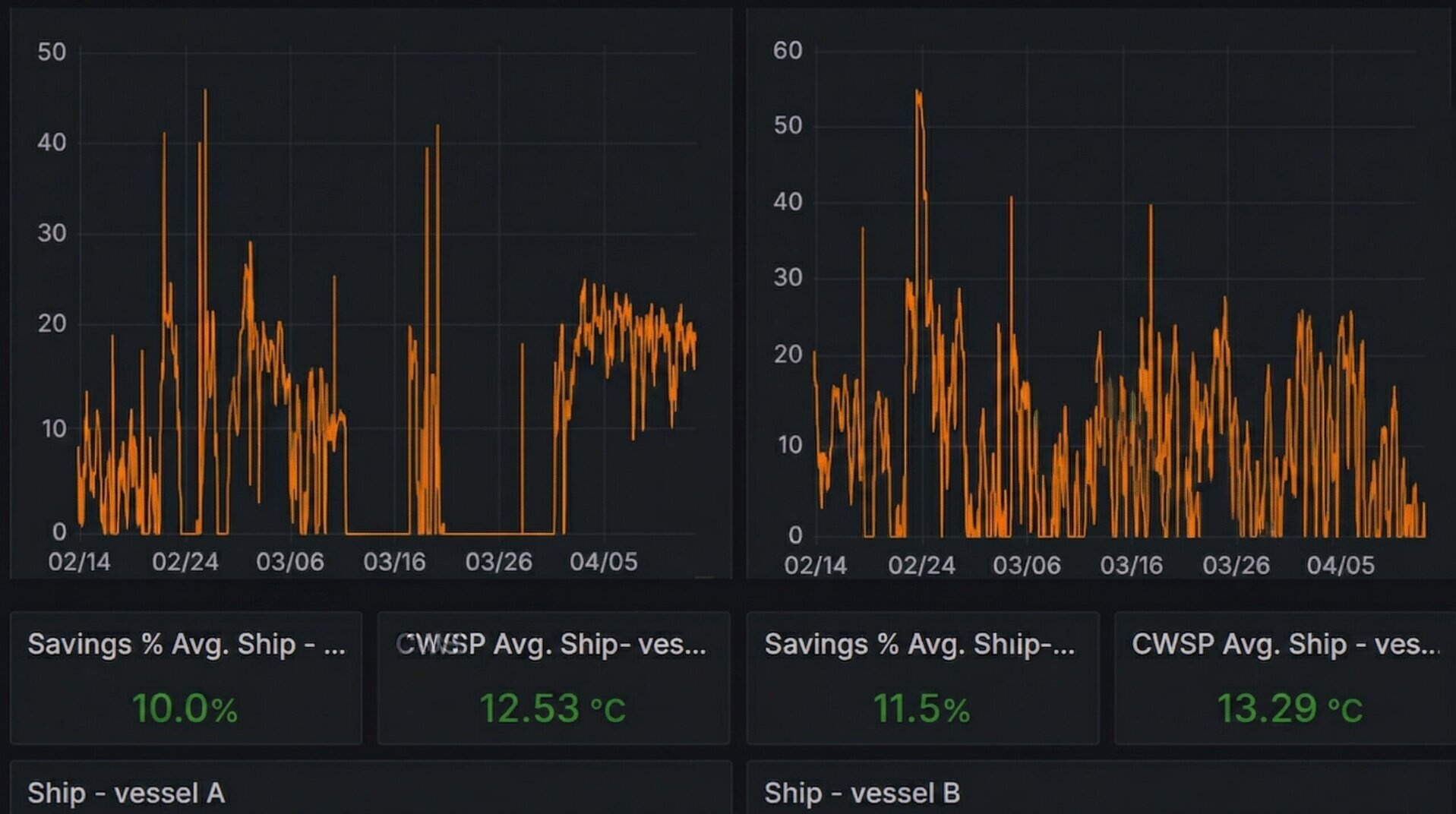
When Arkitech finished its first full-year deployment on MSC Magnifica, the result was the one we had been working toward: roughly 10% reduction in HVAC energy consumption, which was captured continuously over twelve months of normal operations. This validated the concept, but what it did not do on its own, was prove that we could deliver the same result on the next eleven ships. That is what the past year (2025) has been about.
Tzomily Anvar is engineering team lead at Arkitech, and this is a short account of the work behind that scaling step.
From one vessel to a fleet
A successful deployment on a single ship and a reliable deployment across twelve are not the same engineering challenge, even when the optimization logic is identical. The algorithms that delivered the original savings on Magnifica are still the same algorithms running today. Almost everything else underneath them has been built up to operate continuously across a distributed fleet, with enough headroom to absorb the next round of vessels without another foundational rebuild.
The work focused on three things:
- how much sensor data the edge platform could process per minute;
- how much of the onboard hardware that processing was using;
- how much shore-based teams could actually see of what was happening on each ship.
None of these are particularly interesting in isolation. What makes them matter is what the optimization layer is then able to do on top of them.
What the new platform looks like in practice
The current edge platform handles around 2,000 priority sensor readings per minute per vessel, which is the rate the optimization logic needs in order to respond to changing conditions in real time rather than to conditions from several minutes ago. System load on the onboard hardware now sits at a small fraction of available capacity, which means there is room for additional features without putting new equipment onboard. Automated cleanup, data synchronization that adapts to the realities of satellite connectivity, and continuous self-monitoring all run quietly in the background, and shore-based teams can see the whole fleet through real-time dashboards and alerts.
"The current edge platform handles around 2,000 priority sensor readings per minute per vessel."
The clearest moment for me was the day we migrated the first vessel onto the new platform, in early 2026. The CPU graph on the edge device went from a constant pattern of peaks to something close to flat within a few hours, and the system was doing exactly the same work it had been doing the day before. Nothing about the optimization had changed. Only the architecture underneath it had.
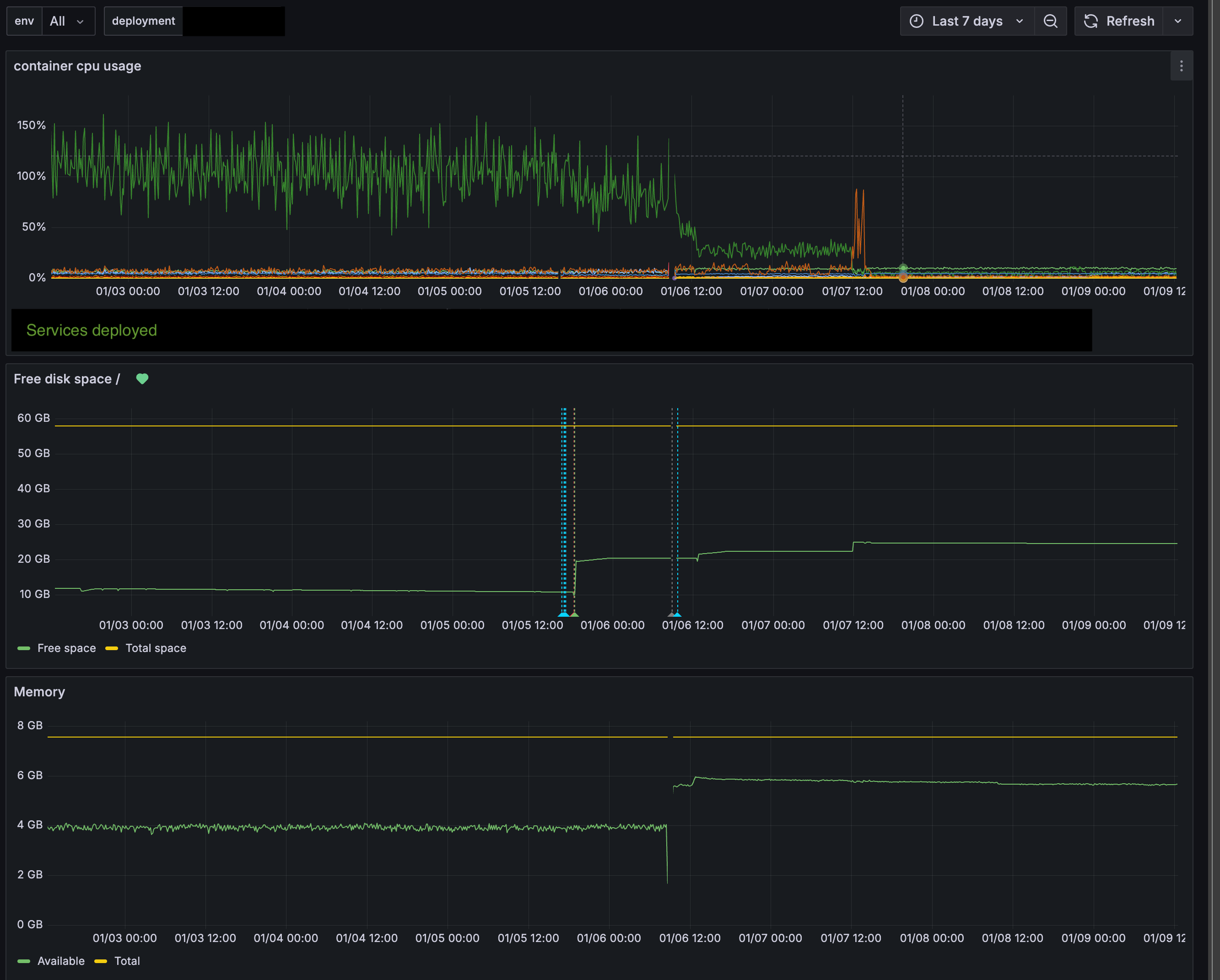
"The CPU graph on the edge device went from a constant pattern of peaks to something close to flat within a few hours."
Why this matters for operations
Reliable infrastructure is not the kind of thing operators see directly when they look at their fleet, but it does decide what the optimization layer is able to do on top of it.
Real-time data that the system can trust is what allows the optimization logic to respond precisely to actual conditions onboard, and that precision is what makes savings consistent rather than variable from week to week. Lower system load on the edge hardware extends its operational life, and it leaves room for the kinds of capabilities that depend on continuous, trustworthy data across a whole fleet, like predictive maintenance and cross-vessel learning.
What this adds up to, from an operator’s point of view, is that the result we validated on Magnifica is now being delivered across twelve vessels with the same level of confidence, rather than being a number that worked once on one ship.
What’s next
Twelve vessels is not the end point. Several more ships are in the deployment pipeline, and the platform is now built to absorb them without the kind of foundational work that the first scaling phase required. The same infrastructure also opens the door to features that depend on having trustworthy, real-time data across an entire fleet at once: tighter predictive models, anomaly detection for maintenance, and cross-vessel learning where improvements made on one ship can be carried over to others.
For now, the milestone is this. The system runs reliably across twelve cruise vessels, the savings are consistent with what we validated at the start, and the foundation is in place for whatever comes next.
For a more detailed engineering account of the architectural patterns behind this work, including async processing, batched database operations, and data synchronization tuned for satellite connections, see the technical deep dive on Tzomily’s Substack.


